Pandas 데이터 전처리 실습
·
Data Science/coding pratice
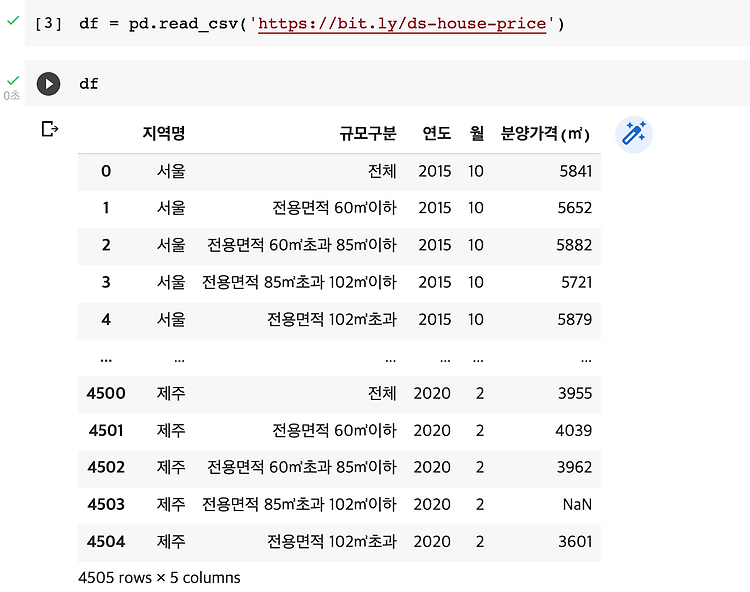
실제 부동산 데이터로 데이터전처리 실습을 진행 1. column 재정의→ rename : column의 이름이 복잡할 경우 재정의를 해준다 #내가짠코드 df.columns = ['지역명', '규모구분', '연도', '월', '분양가격'] >> 이름을 다 넣어줘서 column이름을 새로 부여해줌 #해설 df = df.rename(columns={'분양가격(㎡)':'분양가격'}) 2. column의 datatype 변환: astype df['분양가격'].astype(int) 3. strip으로 공백이 있는 데이터 공백없애기: strip() column의 문자열에 strip을 실행하고자 할 때는 str.strip() df.loc[df['분양가격']==' '] #확인 df['분양가격'] = df['분양가격']...



