
목차
- 데이터프레임 병합(merge): concat 차이 (left, right, inner, outer), column이 다를때 merge
- astype(), dtype() : 데이터 타입 변경
- pd.to_datetime
- dt.함수
- 값을 넣어주는 방법 3가지
- apply: 함수 def 정의하여 적용 ex.성별 남/여를 0,1로 바꾸기 등
- lambda: lambda x: 수식 (함수식 간단히 한줄로)
- map: dict형태로 key, value값에 각각 할당
- 데이터프레임의 산술연산(시리즈)
- column과 column 간 연산
- column과 숫자 간 연산
- 복합연산
- mean(), sum()을 axis 기준으로 연산(열의 총합계, 행의 총합계)
- NaN 값이 존재할경우의 연산
- 데이터프레임과 데이터프레임 간 연산
- 문자열이 포함된 데이터프레임과 데이터프레임 간 연산할 경우 (df+df)
- 문자열이 포함된 데이터프레임에 브로드캐스팅 연산 (df+10)
- column 순서가 뒤바뀐 경우
- 행의 갯수가 다른 경우
- Select_dtypes: 문자형/숫자형 column 선택(include='object') 옵션
- One-Hot encoding: pd.get_dummies, prefix 옵션
Import pandas as pd
1) Merge : DataFrame 병합
concat과의 차이? 합치는 목적과 특정 기준(index)로 합치느냐에 따라 용도가 다르다
- concat: row/column 기준으로 단순하게 이어붙이기
- merge: 특정 고유한 키 값(unique id)을 기준으로 병합한다
예) df와 df2가 '이름'이라는 column이 겹칠때, '이름'을 기준으로 두 데이터프레임을 겹칠 수 있다.
pd.merge(left, right, on = '기준 column', how = 'left/right')
- left와 right는 병합할 두 프레임을 대입
- on에는 병합의 기준이 되는 column 넣어줌
- how에는 left, right, inner, outer 4가지 병합방식 중 한가지 선택
how = 'left' : 왼쪽에 적힌 인자 기준으로 병합
how = 'right' : 오른쪽에 적힌 인자 기준으로 병합
1-1) left/right
ex)

df_right = df2.drop([1,3,5,7,9],axis=0) **df2에서 고의적으로 1,3,5,7,9행을 없애버린 df_right 변수 생성
df_right.reset_index()
>> df.right에는 index number 1, 3, 5, 7, 9 행이 빠짐
| pd.merge(df, df_right, on = '이름', how='left') | pd.merge(df, df_right, on = '이름', how='right') |
|
|
| 왼쪽의 데이터 프레임(df)이 더 많은 행 개수(5개)를 갖고 있기 때문에 존재하지 않는 값은 NaN 값으로 처리됨 <df.right에 없는 이름, 연봉은 df에 있어서 df를 기준으로 채워지지만, df에 '가족수'는 없으므로 nan값이 채워짐> |
오른쪽의 데이터 프레임(df_right)가 행 개수(5개)가 더 적으므로 왼쪽 데이터 프레임(df) 데이터 중 df_right에 없는 행은 drop된다 |
1-2) inner/outer
・ inner : 교집합, pd.merge(df, df_right, on = '이름', how='inner') 겹치는 행(열이 아님)만 나옴, 총 9행
・ outer : 합집합, pd.merge(df, df_right, on = '이름', how='outer') 모두 합한 행이 나옴, 총 14행
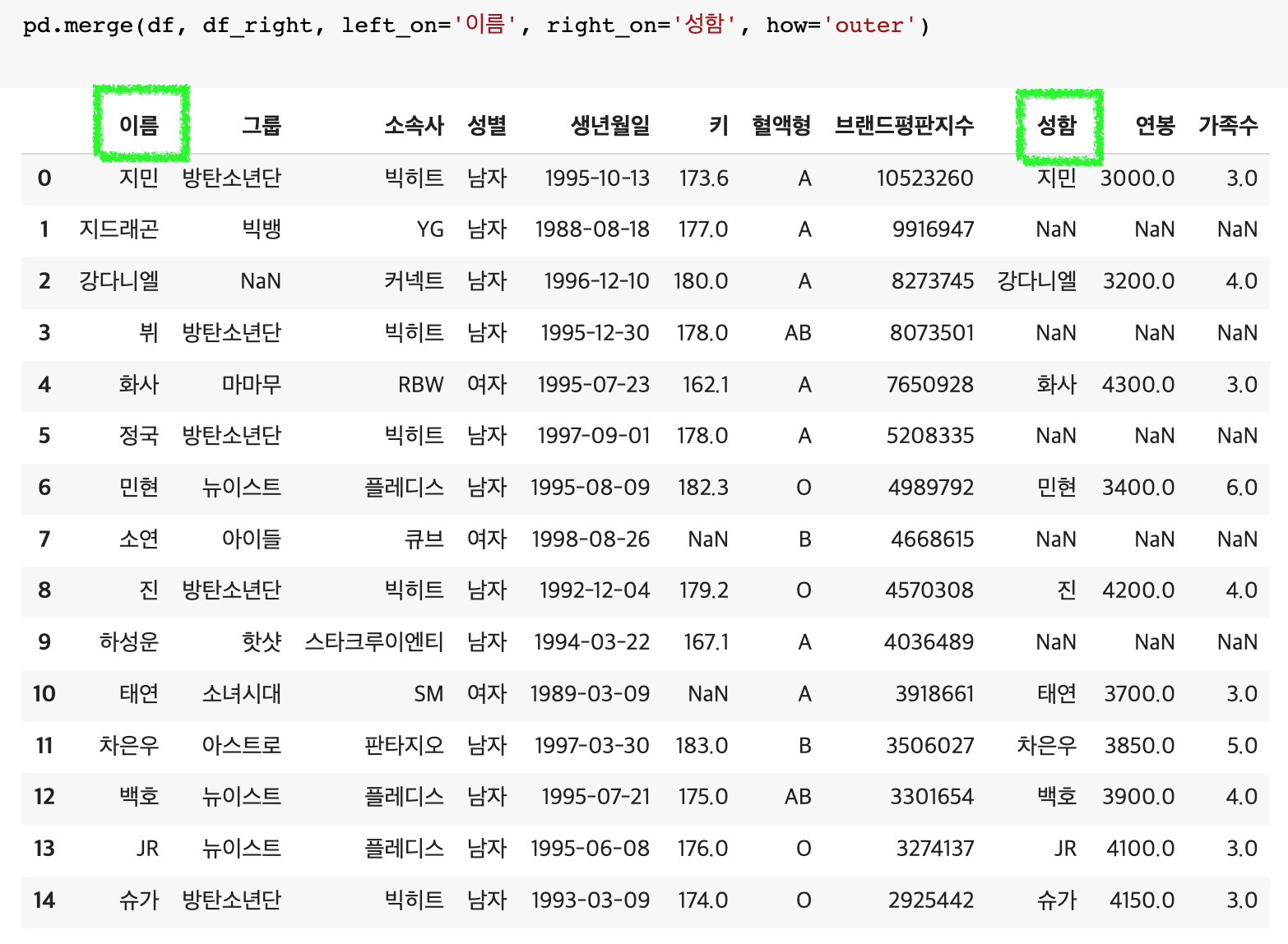
- 합치려는 두 dataframe의 기준(여기서는 이름) 컬럼이 내용은 같은데 컬럼명이 다를 때: left_on, right_on 옵션 사용
>> pd.merge(df, df_right, left_on = '이름', right_on = '성함', how = 'outer')
2) Series Type 변환
*Type 먼저 확인 : df.info()
・ object : 일반 문자열
・ float : 실수
・ int : 정수
・ category : 카테고리
・ datetime : 시간
2-1) type 변화시키기 : astype()
* dtype() : 데이터타입 확인
df['키'].dtypes >> dtype('float64') *Series의 data type 확인
df['키'].astype(int)
**NaN 값이 있을 경우, 변환이 되지 않으므로 NaN값을 -1로 바꿔줌(fillna)
df['키'].fillna(-1, inplace=True) or df['키'] = df['키'].fillna(-1)
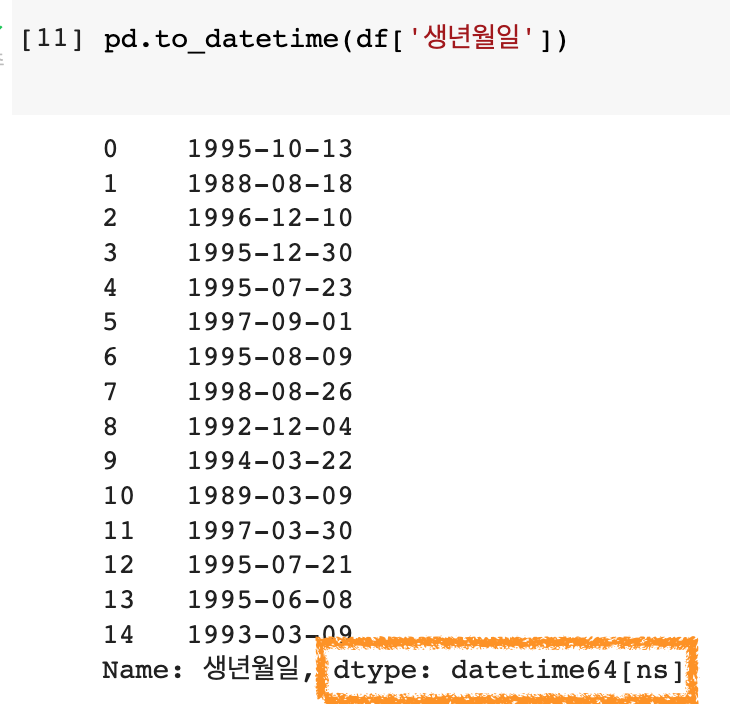
3) Datetime Type : pd.to_datetime(df['컬럼명'])
날짜는 astype으로 변환되지 않음. pd.to_datetime 이용
ex) df['생년월일'] = pd.to_datetime(df['생년월일'])

** datetime만 사용할 수 있는 dt.함수가 있기 때문에 변환한다.
- 연도, 월, 일자, 요일(dayofweek)을 간편하게 뽑을 수 있다.
- 'datetime'의 약자 'dt' 함수를 통해 다양한 정보 뽑기 가능
(0: 월, 1:화 ...)
ex)
df['생년월일'].dt.year
df['생년월일'].dt.month
df['생년월일'].dt.day
df['생년월일'].dt.hour
df['생년월일'].dt.minute
df['생년월일'].dt.second
df['생년월일'].dt.dayofweek **요일
df['생년월일'].dt.weekofyear **1년 기준 몇주차


값을 넣어주는 방법 3가지
1) 함수식 apply
: series, dataframe에 좀 더 구체적인 로직을 적용하고 싶을 때 사용
함수를 먼저 정의해야함(def). 정의한 로직 함수를 인자로 넘겨준다.
1-1) 남/여 문자열 데이터로 구성된 '성별' column을 1과 0으로 바꾸기
- 기존방법
df.loc[df['성별']=='남자', '성별'] = 1
df.loc[df['성별']=='여자', '성별'] = 0
* df = 처리 안해줘도 됨
>> 이건 그 column에 남자, 여자값만 있다고 확신할 때 혹은 위처럼 입력할 경우가 적을때 가능
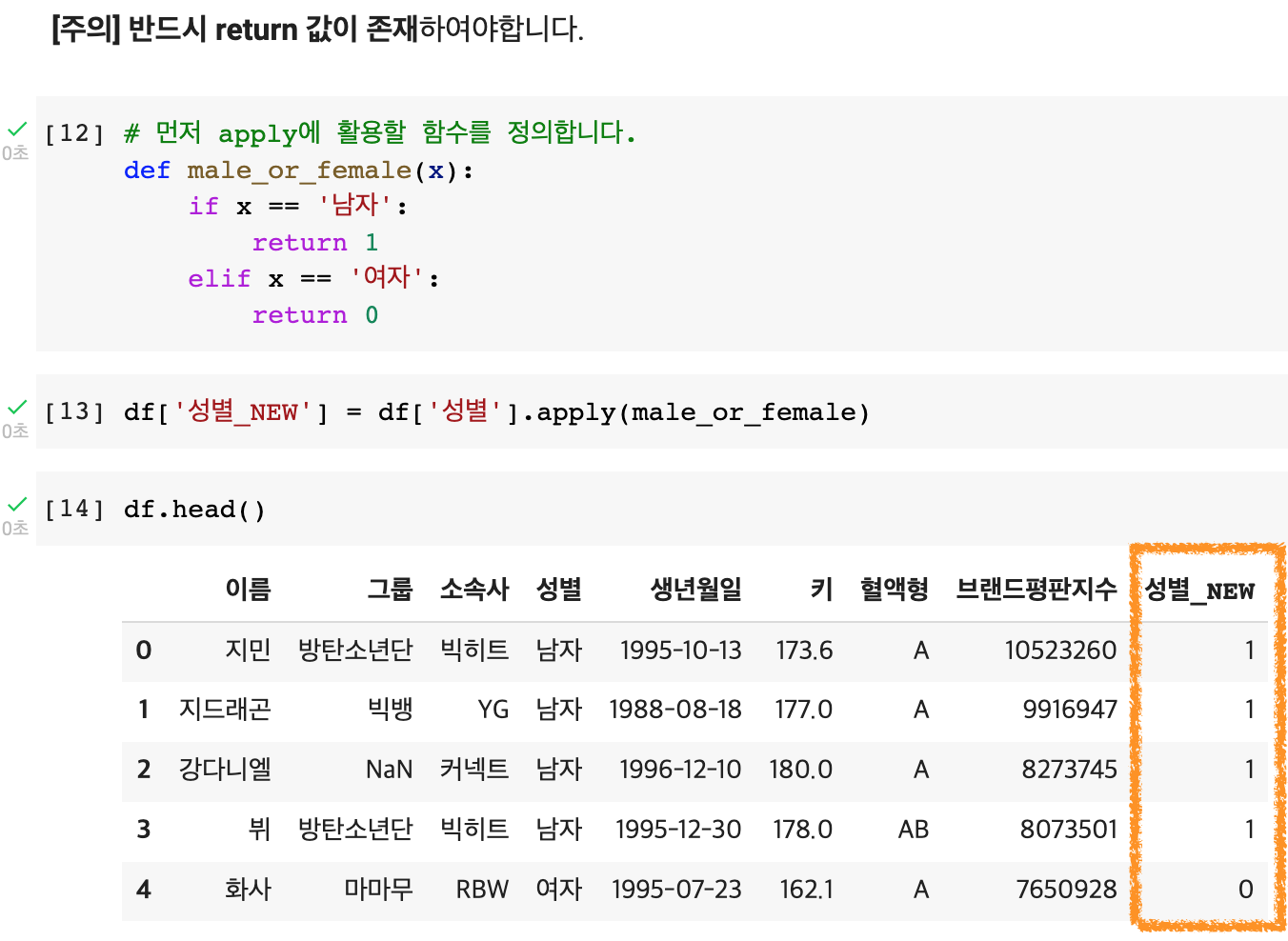
def male_or_female(x): x는 넘어오는 값, 시리즈이므로 df가 아닌 x로 넘겨줌
df['성별'].apply(male_or_female)
1-2) cm당 브랜드 평판지수를 구하시오
def cm_to_brand(df): ** 키, 브랜드평판지수 등 여러 column값이 필요하므로 df로 받음
value = df['브랜드평판지수']/df['키']
return value
df.apply(cm_to_brand, axis=1) 지금은 한 행씩 넘겨줘야하므로(횡으로 처리해야함, 연산방식을 열로 두겠다는 뜻)
즉, df 전체로 받아야할 때는 axis=1을 지정해줌
2) lambda를 이용한 apply : df.apply(lambda x: 넣을 값)
lambda는 한줄로 작성하는 간단 함수식
return을 따로 명기하지 않음
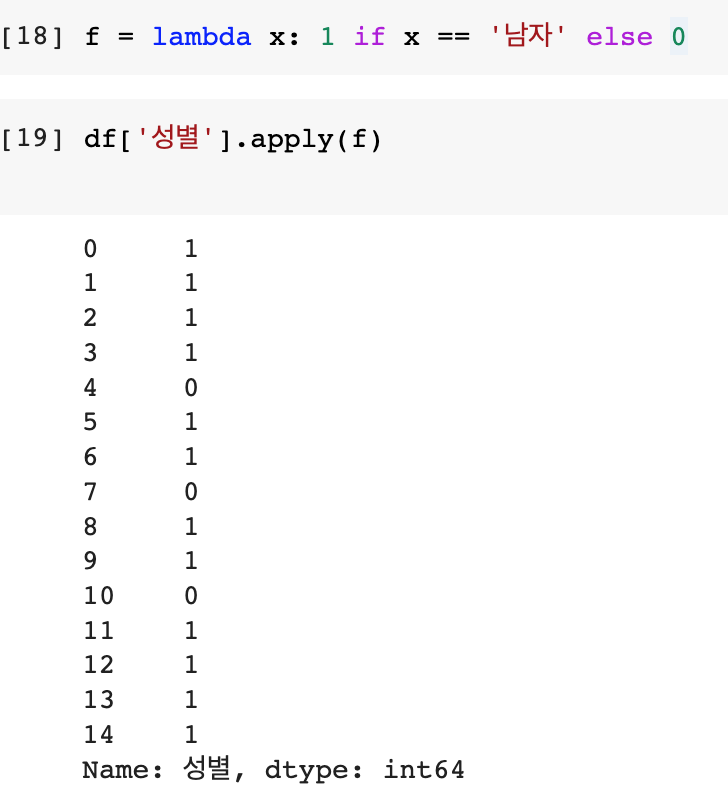
lambda x: 1 if x == '남자' else 0
lambda x: 하나하나 값이 x로 들어간다
x는 1이다, x가 남자면. 그렇지 않으면 0을 준다.
예제.
1번 df['성별'].apply(lambda x: 1 if x == '남자' else 0)
2번 df['키/2'] = df['키'].apply(lambda x: x/2)
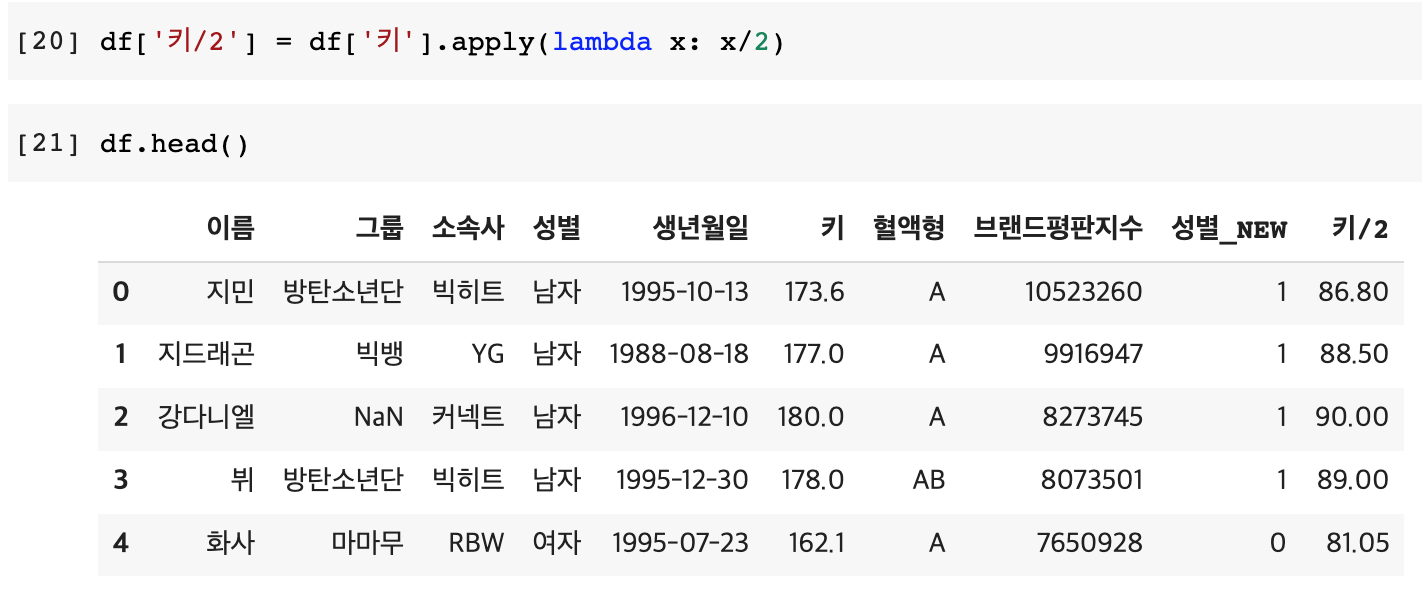
3) map : 값을 맵핑
1:1로 매칭하여 값을 바꿔줘야 할 때 apply보다 편리함
df['column'].map()
맵은 무조건 dictionary 형태로 정의함. 값을 매핑하는 것.
my_map = {
'남자' : 0
'여자' : 1
}
#dict 형태로 가져옴
df['column'].map(my_map)

데이터프레임의 산술연산(시리즈)
임의의 df 생성

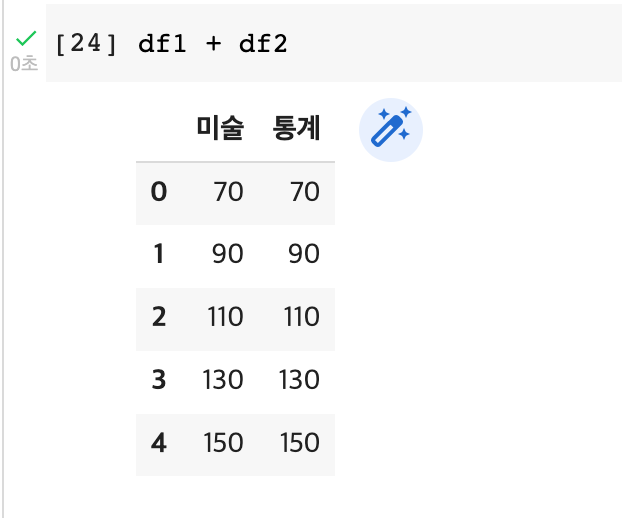
1) Column과 Column 간 연산(+, -, *, /, %)
: 별개의 시리즈로 인식하여 각 행의 숫자들끼리 연산이 된다.
df['통계'] + df['미술']
df['통계'] - df['미술']
df['통계'] * df['미술']
df['통계'] / df['미술']

2) column과 숫자 간 연산(+, -, *, /, %)
df['통계'] + 10
df['통계'] - 10 등등
3) 복합연산
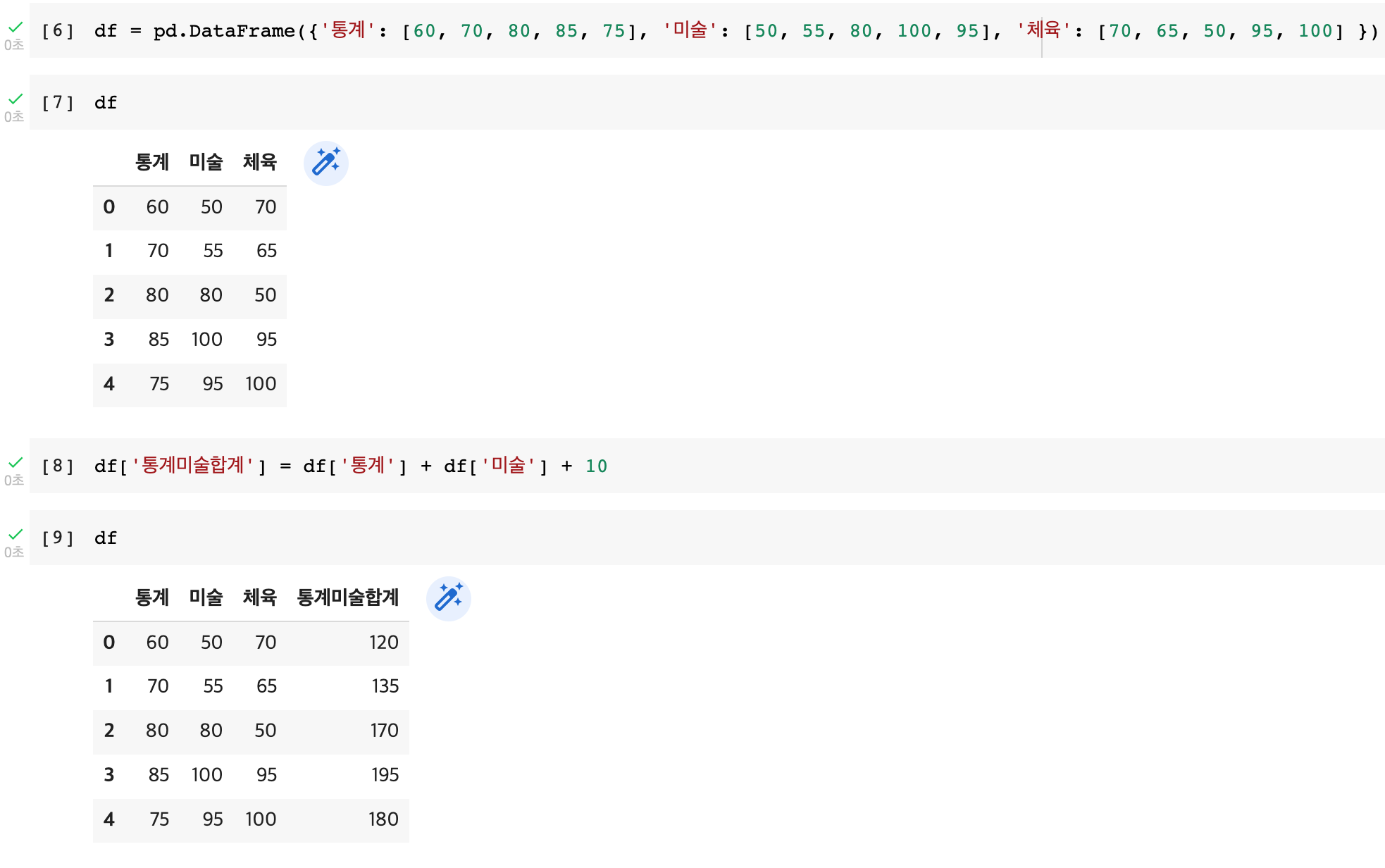
4) mean(), sum()을 axis 기준으로 연산 ★
・ df.mean(axis=0) : axis = 0이므로 row(행) 기준이다. 행의 총합계, 한 열에 대한 1행부터 n행까지의 전체 합
・ df.mean(axis=1) : axis = 1이므로 column(열) 기준이다. 한 행에 대한 1열부터 n열까지의 전체 합
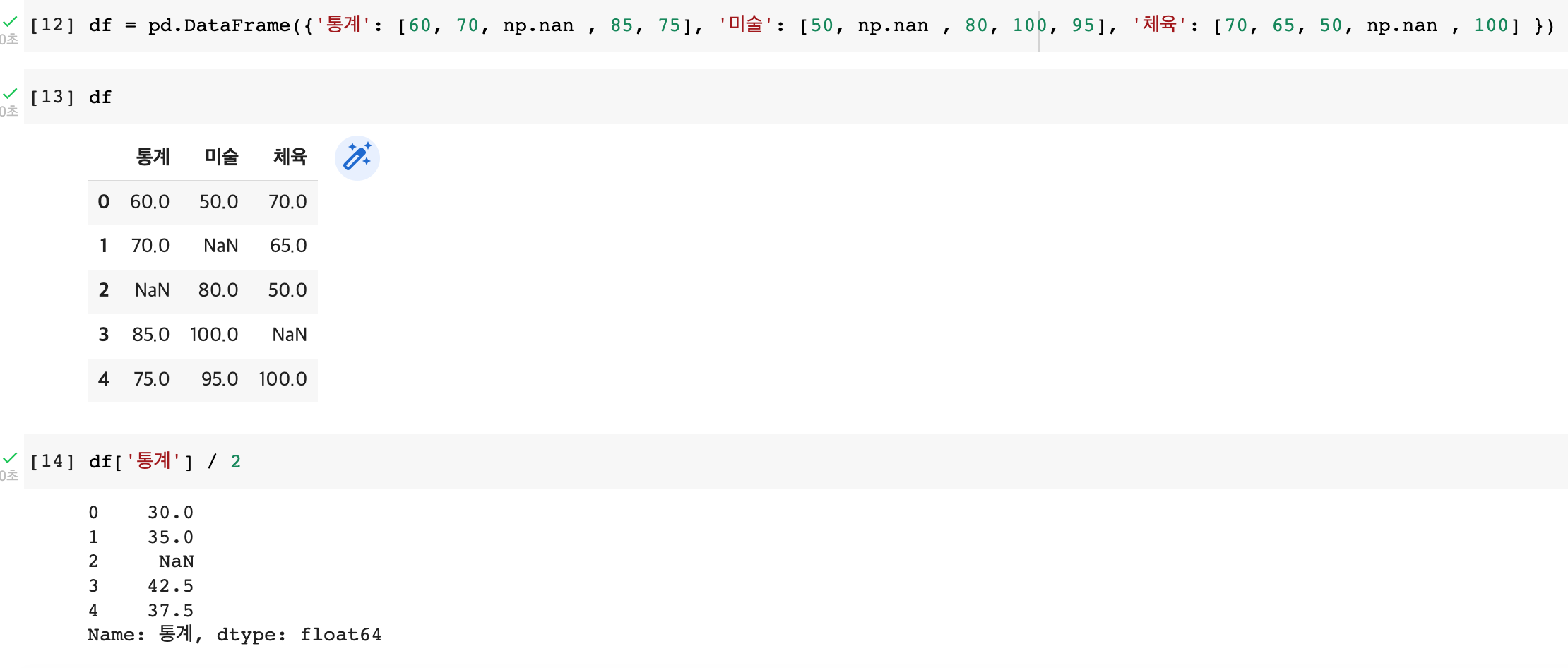
5) NaN 값이 존재할 경우 연산
nan값은 그냥 nan값 그대로 출력된다. /2나 *2, +2, -2 전부 안됨
Dataframe과 Dataframe간의 연산
1) 문자열이 포함된 데이터프레임과 연산할 경우 ⟶ error
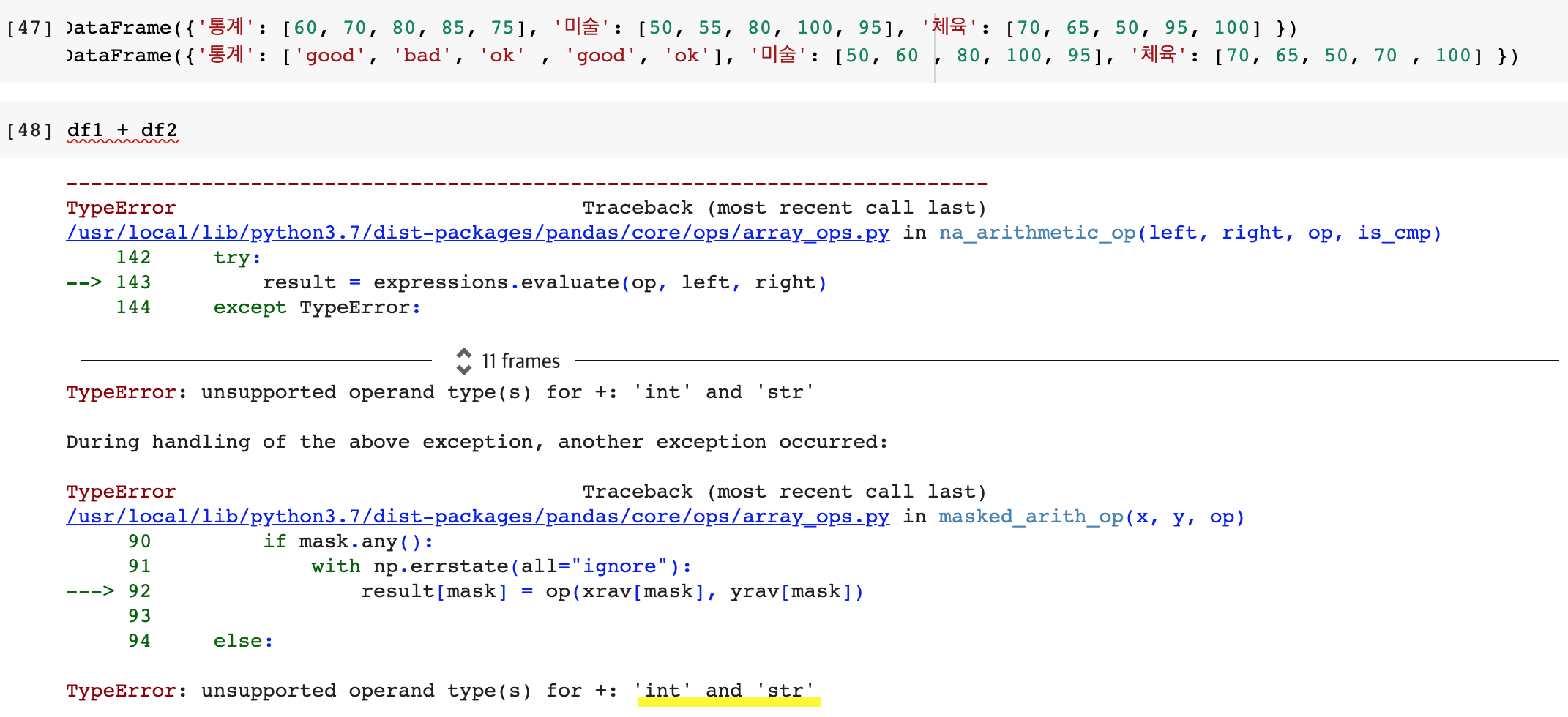
2) 문자열이 포함된 데이터프레임의 브로드캐스팅 연산 ⟶ error
*broadcasting: 변수에 numpy array나 pandas series/dataframe을 지정한 후 연산하는 방법
ex) df + 10
이것 또한 문자열이 있어 불가능하다
3) column 순서가 뒤바뀐 경우
: 알아서 column명이 일치하는 것끼리 더해줌

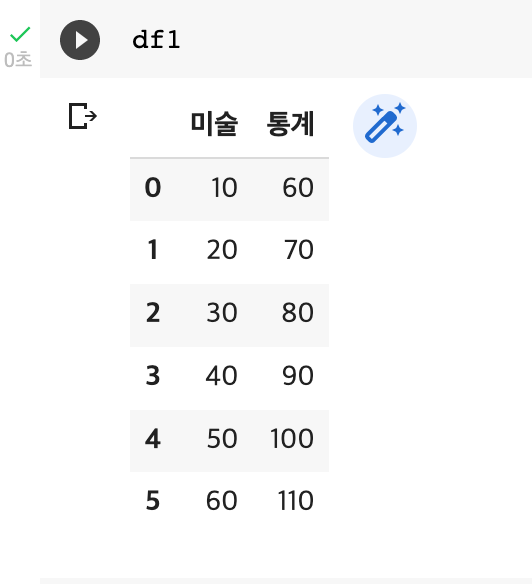
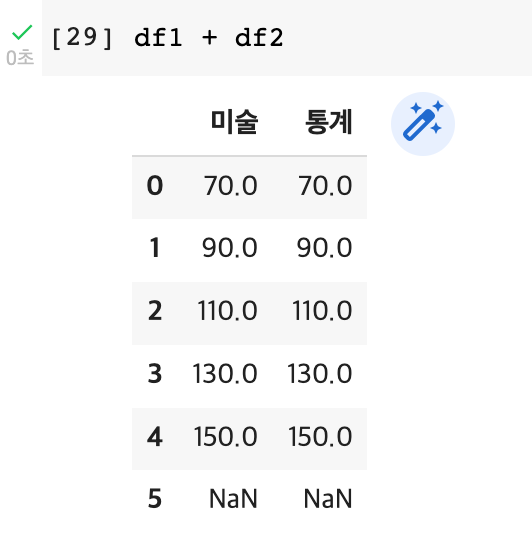
4) 행의 개수가 다른 경우
: 행이 많은 것을 기준으로 행이 추가가 되지만, 부족한 행은 더할 값이 없으므로 NaN으로 출력됨

Select_dtypes
현재 데이터의 컬럼이 10만개, 100만개가 되어도 숫자형/문자형 컬럼을 따로 분리해내 전처리를 수행할 수 있음
1) 데이터 타입별 column 선택 : select_dtypes()
object와 object가 아닌 것으로 나뉜다. 알고리즘에 숫자형 column을 넣어줘야하는데 문자열은 컴퓨터가 인식하지 못하므로 숫자형으로 바꿔서 넣어줘야한다. 그 때 사용함.
1-1) 문자열이 있는 column만 선택: include, exclude 옵션
df.select_dtypes(include = 'object') 문자형 컬럼만 나옴
df.select_dtypes(exclude = 'object') 숫자형 컬럼만 나옴
・ 문자열이 포함된 dataframe의 연산으로 발생되는 error를 피하기 위해 사용
ex) df + 10 > error
df.select_dtypes(exclude='object') + 10
・ 숫자형/문자형 컬럼의 컬럼명만 가져오고 싶을 때: columns 옵션
ex) df.select_dtypes(exclude='object').columns >> 숫자형 컬럼의 이름만 출력
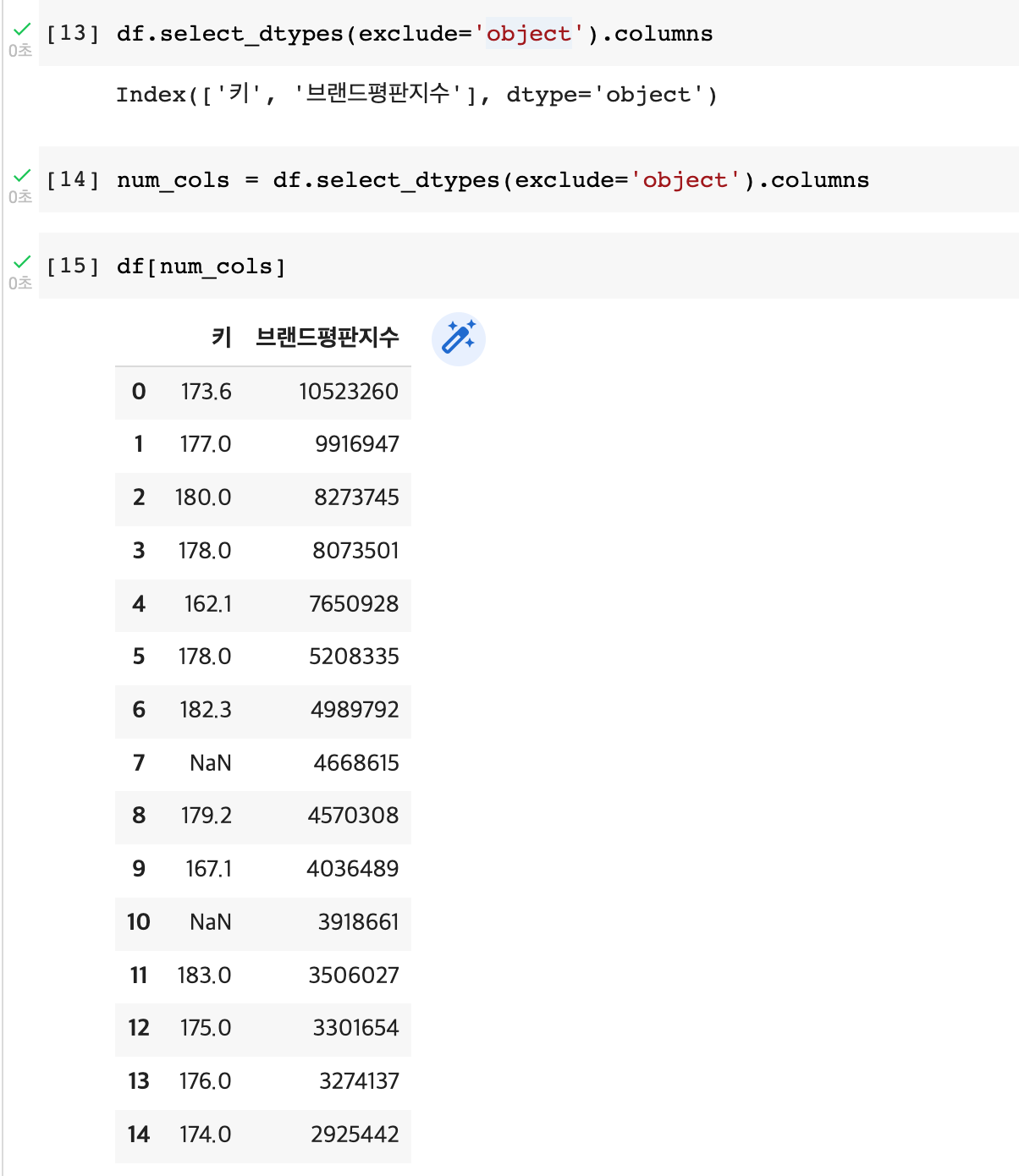
**새로운 dataframe으로 가져오기
num_cols = df.select_dtypes(exclude='object').columns
df[num_cols]
or
num_cols = df.select_dtypes(exclude='object')
num_cols
(밑에건 임의로... 작성해봤더니 나왔다. 맞는지는 모름?)
>> 위에는 columns명만 받았기때문에 df[변수명']으로 불러오기
아래건 columns명을 지정안했으므로 데이터프레임 형식으로 num_cols 변수에 지정됨
One-hot-encoding (여기선 이해만 하고 넘어가기)
한 개의 요소는 True, 나머지 요소는 False로 만들어주는 기법, 한 개의 요소만 핫해서 원-핫-인코딩
ex)
blood_map = {
‘A’ = 0,
'B’ = 1,
‘AB’ = 2,
‘O’ = 3
}
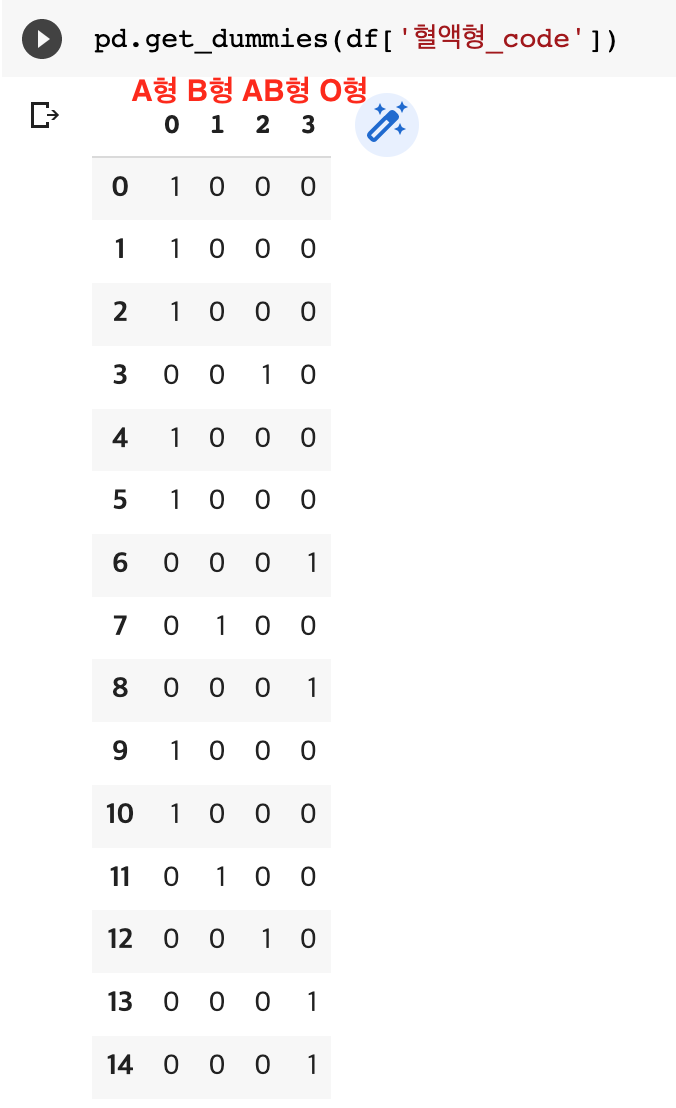
df[‘혈액형_code’] = df[‘혈액형’].map(blood_map) ** 매핑
df[‘혈액형_code’].value_counts() ** 개수 확인
만약 df[‘혈액형_code’]를 머신러닝 알고리즘에 넣어 데이터 예측을 지시한다면, 컴퓨터는 ‘혈액형_code’ 안에서 값들간의 관계를 스스로 형성하게 된다. 이 때 우리는 사실 독립적인 값을 숫자형으로 바꿨을 뿐인데, B 형이 1 이고 AB 형이 2 이므로 A+AB 형이 O형이 된다고(3값을 가진다고 정의해놨으니까) 컴퓨터가 스스로 계산해버릴 수 있다.
그래서 우리는 A 형이 있는 컬럼, B 형이 있는 컬럼 ... 등 4 가지의 컬럼을 별도로 만들어준다. 그리고 1 개의 컬럼만 True 값을 준다.
>> 그래서 더미변수로 만들어줌 : pd.get_dummies()
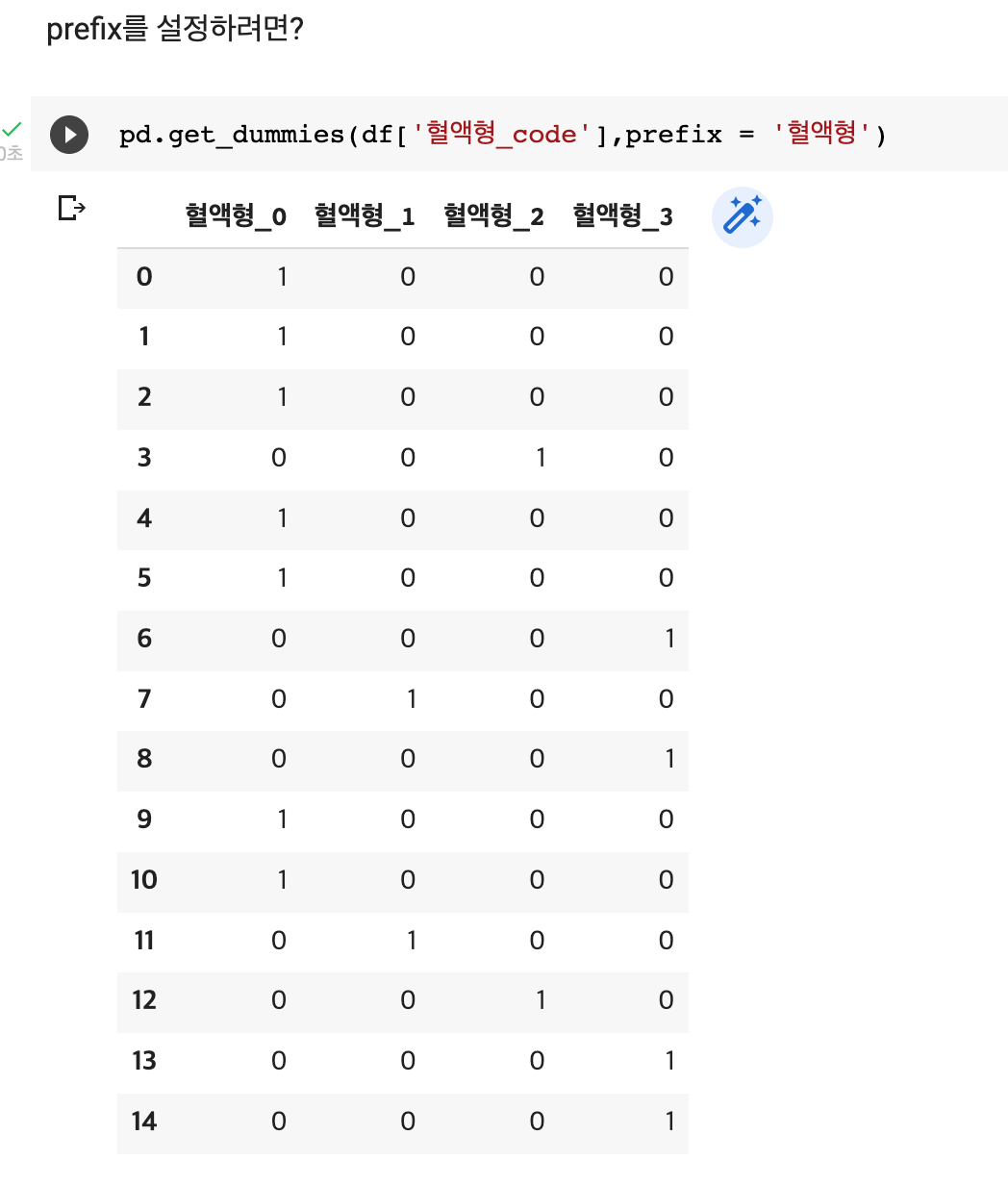
pd.get_dummies(df['혈액형_code', prefix = '혈액형')
**prefix 옵션: 더미변수의 column에 보기 편하게 이름 붙여줌
'Data Science > coding pratice' 카테고리의 다른 글
| Pandas 데이터 전처리 실습 (0) | 2022.05.17 |
|---|---|
| Numpy 03 (0) | 2022.05.01 |
| Numpy (0) | 2022.04.22 |
| pandas 복습 2 (0) | 2021.02.24 |
| Pandas 복습 1 (0) | 2021.02.16 |