
Today's paper
고객의 특성 정보를 활용한 화장품 추천시스템 개발 - 김효중, 신우식, 신동훈, 김희웅, 김화경
오늘은 지금 읽고 있는 논문 공부 기록을 하겠다.
저작권상 자세한 설명은 할 수 없고, 읽는 과정에서 막히는 개념을 그때그때 학습하려한다.
참고링크
https://huidea.tistory.com/263
[Machine learning] 추천 알고리즘의 기초 총정리 - Collaborative filtering , Matrix Factorization, SVD, Factorization
0. 추천 알고리즘의 종류 https://towardsdatascience.com/various-implementations-of-collaborative-filtering-100385c6dfe0 1) 협업 필터링(Collaborative Filtering) • Memory Based Approach : User-based Filtering, Item-based Filtering • Model Ba
huidea.tistory.com
Abstract
- 뷰티 제품군 특성 기반 개인 취향 및 고객별 정보를 고려하여 데이터 기반 맞춤서비스 제공 필요
- 딥러닝 기법을 활용한 제품 검색기록 및 개인 사용자의 피부타입, 고민 등 콘텍스트 정보를 함께 반영하여 심층신경망 기반의 추천시스템 모델을 제시(NCF-CI)
목차
0. NCF-CI란?
1. 콜드 스타트(cold start)란?
2. 임베딩 레이어
3. 임베딩 전 데이터 전처리
0. NCF-CI?
추천시스템(Recommdation System)의 모델기반 협업 필터링 중 심층신경망 협업필터링(Neural Collaborative Filtering) 모델 활용
- 추천시스템

- 내용 기반 추천(Contents-based Recommenation)
> 주요활용사례: ① 비정형 텍스트 기반 TF-IDF 활용 추천 ② 아이템 특성 기반 군집화 추천 - 협업 필터링(Collaborative Filtering)
: 사용자・아이템 행렬(User-item Matrix)을 통해 산출한 사용자 및 제품간 유사도 활용
1) 메모리 기반 협업필터링
: 콜드 스타트 문제 및 아이템 종류 및 사용자 수 급증에 따라 알고리즘 구현을 위한 계산량 급증 한계점 존재
① User-based Filtering ② Item-based Filtering
2) 모델 기반 협업필터링
: 콜드 스타트 해소를 위한 방안
① 행렬분해법(Matrix Factorization) ② 딥러닝 기반 협업필터링
③ 심층신경망 협업필터링 모형 등장(NCF): 행렬분해법이 지닌 강점을 인공신경망 형태로 나타내어 딥러닝 기반 협업필터링 방식으로 표현
심층신경망 협업필터링의 장점
사용자와 아이템 데이터를 임베딩하여 사용자 잠재벡터와 아이템 잠재벡터로 표현, 이를 다층 신경망 퍼셉트론(MLP)에 통과시켜 사용자와 아이템 간 비선형적 상관관계를 학습하여 기존의 메모리기반 협업필터링 문제점을 보완함
※ 행렬분해법의 경우, 메모리 기반 협업필터링에서 사용된 사용자-아이템 행렬을 사용자 잠재벡터와 아이템 잠재벡터로 분해하여 손실함수를 통해 최적화되어 새롭게 산출된 행렬을 기반으로 아이템을 추천함
1. 콜드 스타트란?
cold start, 상품 추천을 위한 데이터 정보가 충분치 않아 해당 유저에게 상품을 추천하지 못하는 문제가 생기는 것을 말한다.
2. 임베딩 레이어(Embedding layer)
https://www.youtube.com/watch?v=hR8Rvp-YNGg
임베딩이란? 자연어를 기계가 이해할 수 있는 숫자로 나열한 벡터화 과정
문자입력에 대해 학습을 요할 때 필요한 레이어
단어를 벡터화 시키는 기술
2-1) 인코딩(encoding)
기계는 자연어를 이해할 수 없음, 데이터를 기계가 이해할 수 있도록 숫자 등으로 변환해주는 작업이 필요하다. 이러한 작업을 인코딩이라 한다. 텍스트처리에서는 주로 정수 인코딩, 원 핫 인코딩을 사용한다.
- 정수 인코딩: 각 단어와 정수 인덱스를 연결하고, 토큰을 변환해주는 인코딩
unique >> ['평생', '오늘을', '꿈을', '살아라.', '살', '것처럼', '죽을', '그리고', '내일', '꾸어라.']
token2idx = {} #dict 생성
for i in range(len(unique): # len(unique)가 10이므로 range는 0~9
token2idx[unique[i]] = i
# i = 0 일때, token2idx[unique[0]] = 0이 되므로, unique[0]은 '평생'이니까 token2idx['평생'] = 0이 됨. dict값의 key와 value값이 각각 {'평생' : 0}으로 지정됨
- keras 이용한 정수 인코딩
- 정수인코딩: 정수인코딩은 단어에 정수로 레이블을 부여
- dictionary, nltk 패키지를 이용한 방법도 있지만, keras에서는 텍스트처리에 필요한 도구들을 지원
- 해당 도구는 자동으로 빈도가 높은 단어의 인덱스는 낮게끔 설정한다
- 원핫 인코딩(one-hot encoding): 한 개(1)만 활성화, 더미변수
단점: 문장이 길어질 때 메모리낭비가 심하다.
https://www.youtube.com/watch?v=MiKh_vEZcTY
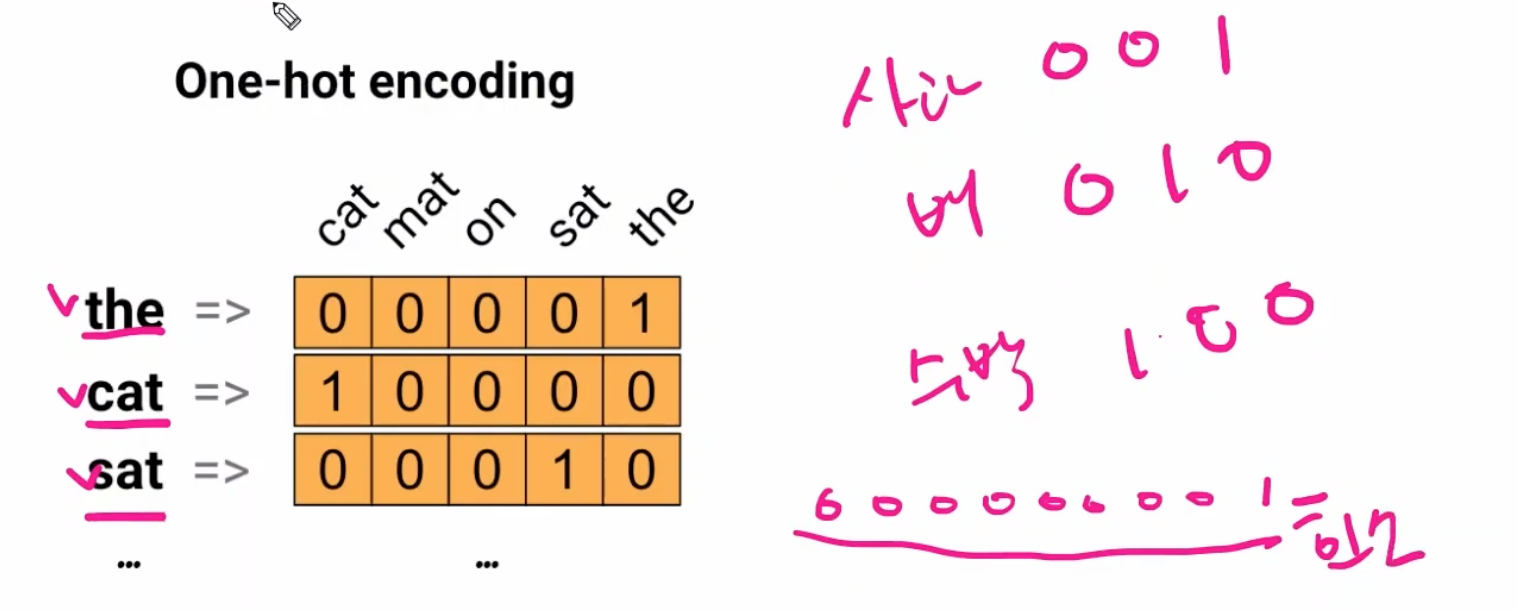
- 단어 인코딩
장점: 단어 간 유사성을 알 수 있다.
3. 임베딩 전 데이터 전처리: 3가지 방법
1) 문장 토큰화 -> 2) 문자인코딩(단어에 인덱스 할당) -> 3) 길이를 똑같이 맞춰준다
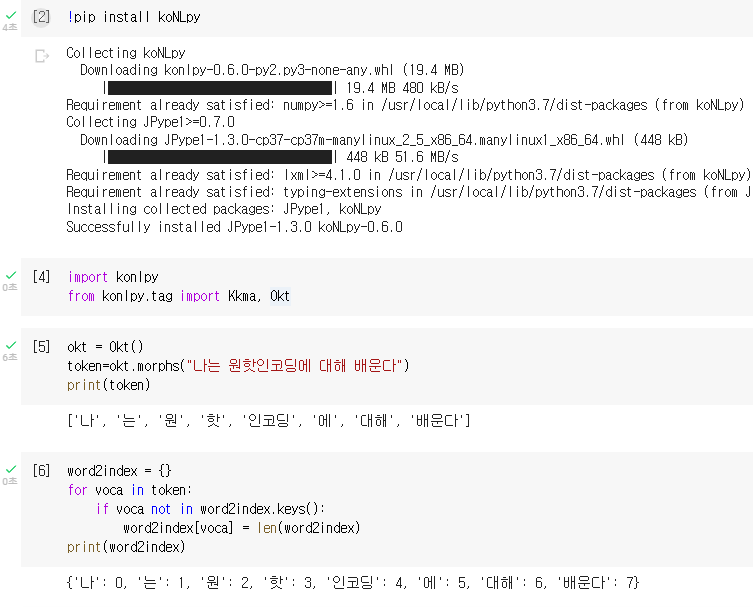
** konlpy(코엔엘파이) 라이브러리를 통해 문장 토큰화하여 원핫인코딩 진행하는 방법
https://blog.naver.com/gfr897/222350624189
[딥러닝] - 원-핫 인코딩(One-Hot Encoding) 정의
안녕하세요 시아입니다:) 단어 집합(vocabulary)에서는 기본적으로 book과 books와 같이 단어의 변형 형태...
blog.naver.com
https://blog.naver.com/ghkduse56/222478477929
<자연어처리/코랩>koNLpy(코엔엘파이) 라이브러리 설치 /kkma/okt/형태소
koNLpy(코엔엘파이) 라이브러리 : 한국어 형태소 분석기로서, 한글 자연어 처리를 위해 만들어진 라이브...
blog.naver.com
↑Kkma, Okt, 공백 토큰화 비교한 사이트
!pip install koNLpy #knNLpy 라이브러리 설치
from konlpy.tag import Kkma, Okt #필요한 라이브러리 import
#문장토큰화
1) Okt방식
okt = okt()
token = okt.morphs("나는 원핫인코딩에 대해 배운다")
print(token)
print("okt.morphs의 결과= \n", token)
2) Kkma방식
morphs_kkma = kkma.morphs(text)
print("kkma.morphs의 결과= \n", morphs_kkma)
**okt.morphs(): 형태소 분석
okt.nouns() #명사 분석
okt.phrases() #어절 분석
okt.pos() #각 품사를 태깅 역할. 텍스트를 형태소 단위로 나누고, 나눠진 각 형태소를 품사랑 같이 리스트화
옵션 norm, stem, join join : 나눠진 형태소와 품사를 ‘형태소/품사’ 형태로 같이 붙여서 리스트화
3) 비교(공백 단위로 분할)
result = text.split()
print("공백단위로 분할한 결과= \n", result)
#각 토큰에 고유한 인덱스(index) 부여: 정수인코딩
word2idx = {}
for voca in token:
if voca not in word2idx.keys(): #word2idx의 key값에 voca가 없으면
word2idx[voca] = len(word2idx) #딕셔너리에 <voca(변수안에 있는 단어) : len(word2idx)> 쌍 추가
print(word2idx)
'Data Science > Paper' 카테고리의 다른 글
| paper study 03 - 프로모션이 있을 때 SKU 수요 예측 (0) | 2023.02.27 |
|---|---|
| paper study 02 - 텍스트마이닝 기반 사용자 경험 분석 및 관리: 스마트 스피커 사례 (0) | 2023.02.21 |