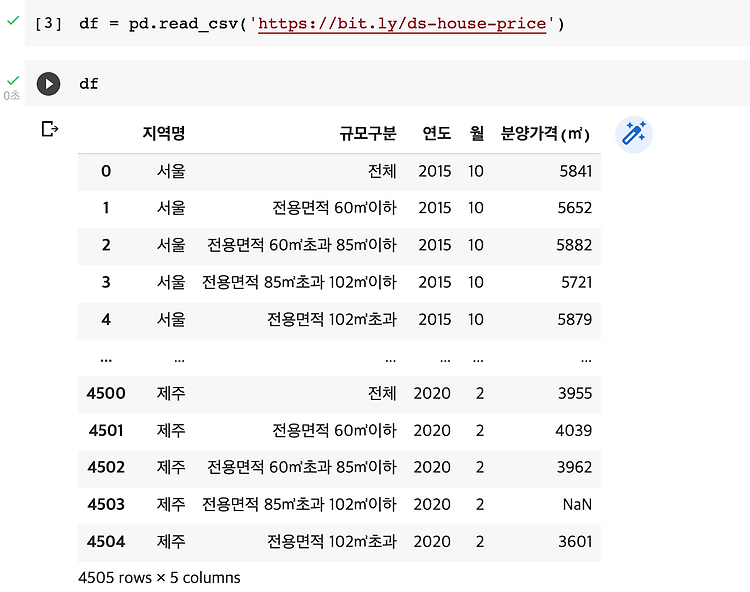
ML 0. 통계분석
·
Data Science/ML
통계분석(Statistical Analsis) 1. 통계학과 기술통계 2. 확률분포 3. 통계적 추론과 통계적 검정 1. 기술통계 데이터의 속성을 특정한 통계량을사용해 정리, 요약, 설명하는 방법 중심척도 중심경향성: 중심적인 경향을 나타내는 주요한 기술통계 산술평균, 중앙값, 최빈치 산포척도 데이터가 퍼져있는 정도를 설명하는 기술통계 범위, 분산, 표준편차, 사분위수 범위(IQR) 분포모양 데이터가 퍼져있는 형태를 나타낸 것 도수분포, 비대칭도(왜도, 치우친 정도), 첨도(뾰족한가 완만한가) 1) 산포척도 - 범위: 최대값과 최소값의 차이 - 제곱의 합(Sum of Squares) 편차는 다 더하면 0이 되는 딜레마가 생긴다 → MSE(제곱하여 합) / MAE(절대값의 합) 잘 알려진 예는 표준편차, ..